This post describe the process of identifying and profiling an inefficient part of GnuTLS. The tool I’m using is callgrind. I won’t describe the tool in detail since I’m not a callgrind expert, instead the focus is on the methodology in finding and fixing a problem. My hope is that this is useful as an insight to how maintainers go about fixing a performance-related problem. It also demonstrates how immensely useful tools like valgrind and callgrind are.
Today I stumbled over something as rare as a post that contains example code to reproduce a problem. The post was written by Edgar Fuß on the openldap list: link to edgars post. First, there is something to be learned here: if there hadn’t been code in that post, I would most likely have ignored it because it is too much trouble for me to understand and duplicate the problem. Especially when this isn’t a real GnuTLS bug report, but just discussion on a non-GnuTLS mailing list. By posting such example code, it was easy for me to compile and run it. As it turned out, the code was very slow and my curiosity peeked. Edgar’s bug triggering code was (somewhat modified for readability):
d = opendir("/etc/ssl/certs");
gnutls_certificate_allocate_credentials(&ca_list);
while ((dent = readdir(d)) != NULL) {
sprintf(ca_file, "/etc/ssl/certs/%s", dent->d_name);
stat(ca_file, &s);
if (!S_ISREG(s.st_mode)) continue;
gnutls_certificate_set_x509_trust_file(ca_list, ca_file,
GNUTLS_X509_FMT_PEM);
}
closedir(d);
If you aren’t familiar with GnuTLS, I’ll describe what the code is intended to do. The code will iterate over all files in /etc/ssl/certs/ and calls gnutls_certificate_set_x509_trust_file for each file. That function will read one or more X.509 CA certificates stored in the file, and add it to the CA trust store inside GnuTLS. The files are typically small (1-2kb) but contain base64 encoded ASN.1 data which is decoded by GnuTLS. The CA trust store is used to determine whether to trust a client or server’s certificate or not. While this is typically only done at startup, and not during each TLS connection, it is not particulary performance critical. Still, if it is excessively slow it will slow down application startup.
On my system (x86 Debian testing) the /etc/ssl/certs directory contains 206 files. I compiled the test code and ran it:
jas@mocca:~$ gcc -o foo foo.c -lgnutls
jas@mocca:~$ time ./foo /etc/ssl/certs/
real 0m40.821s
user 0m40.743s
sys 0m0.036s
jas@mocca:~$
40 seconds! Delaying startup of an application by that amount is pretty significant, so I understand this was considered a problem.
I became curious how much memory the process was using. If my machine had started paging (unlikely with 2GB but you never know), I could understand if it was this slow. However, the top output was relatively stable:
PID USER PR NI VIRT RES SHR …
6538 jas 20 0 5548 3668 752 …
In other words, the virtual size was about 6MB, which seemed normal. My next step was to run the binary under valgrind, to possibly detect any memory corruption or other problem that might explain the slowness. Valgrind slows down execution significantly, and after around 7 minutes I gave up and modified the code slightly so that it only iterated over the first couple of files. After running valgrind once, I discovered that the code didn’t call the needed gnutls_certificate_free_credentials() and gnutls_global_deinit(). You can download the updated example code gnutls-callgrind.c. The valgrind suppressions file to shut up some known libgcrypt internal memory leaks is available as libgcrypt.supp.
jas@mocca:~$ gcc -o foo foo.c -lgnutls
jas@mocca:~$ time ./foo
real 0m0.222s
user 0m0.216s
sys 0m0.004s
jas@mocca:~$ time valgrind –suppressions=foo.supp –quiet ./foo
real 0m7.619s
user 0m7.488s
sys 0m0.108s
jas@mocca:~$
Nice! No memory leaks. We can now be relatively certain that the problem is really with the intention of the code, rather than some memory related bug. Given that we use C here, you want to rule out such problems early on because they are a nightmare to debug.
Now for the performance tuning session. Let’s run callgrind on the application. First, we must make sure we use a GnuTLS compiled with debugging information. The easiest way to do this is to compile it against the static libgnutls. Proceed as follows.
jas@mocca:~$ gcc -o foo foo.c /usr/lib/libgnutls.a -lgcrypt -ltasn1 -lz
jas@mocca:~$ time valgrind –tool=callgrind –quiet ./foo
real 0m18.292s
user 0m18.129s
sys 0m0.084s
jas@mocca:~$ ls -la callgrind.out.8164
-rw——- 1 jas jas 69654 2008-02-26 21:46 callgrind.out.8164
jas@mocca:~$ kcachegrind &
As you can see, execution time is even slower than with valgrind. The profile data output file is quite small. Running kcachegrind yields this output (click to enlarge):
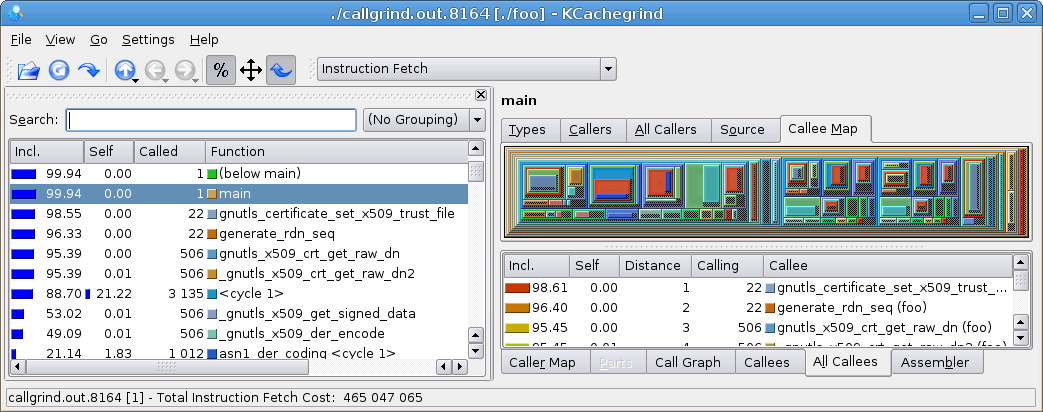
The amount of information in kcachegrind can be overwhelming at first. However, the interesting values are in the percentages and call counts columns to the left. It tells us that gnutls_certificate_set_x509_trust_file() was invoked 22 times, and that 98% of the time is spent there. (If you are surprised by the 22, look at the code, the variable i starts at 0, and the loop is run until it is larger than 20, i.e., it is 21, which makes for 22 iterations in the loop.) The code for that function looks like:
{
int ret, ret2;
size_t size;
char *data = read_binary_file (cafile, &size);
if (data == NULL)
{
gnutls_assert ();
return GNUTLS_E_FILE_ERROR;
}
if (type == GNUTLS_X509_FMT_DER)
ret = parse_der_ca_mem (&res->x509_ca_list,
&res->x509_ncas,
data, size);
else
ret = parse_pem_ca_mem (&res->x509_ca_list,
&res->x509_ncas,
data, size);
free (data);
if (ret < 0)
{
gnutls_assert ();
return ret;
}
if ((ret2 = generate_rdn_seq (res)) < 0)
return ret2;
return ret;
}
The callgrind output tells us that 96% of the programs time is spent inside the 22 calls to generate_rdn_seq(), which in turn call gnutls_x509_crt_get_raw_dn a total of 506 times. The calls to gnutls_x509_crt_get_raw_dn make up 95% of the program's execution time.
We can now conclude that the problem is inside the generate_rdn_seq() function, and not in the rest of the gnutls_certificate_set_x509_trust_file() function body. Given that 95% of the time is actually in a function that generate_rdn_seq calls (i.e., gnutls_x509_crt_get_raw_dn), the problem is either that the function is called too many times or that it is too slow.
Some words about what generate_rdn_seq() is intended to do: it pre-computes a list of names of the CA certificates. In TLS servers, this list of names of trusted CAs is sent to clients. The list is used by the client to find a client certificate issued by a CA that the server recognize. To avoid computing the list every time it is needed (i.e., for every connection), GnuTLS pre-computes this and store it in the credential structure. One credential structure can be associated with one or more TLS sessions.
We are now prepared to look at the code for generate_rdn_seq:
static int
generate_rdn_seq (gnutls_certificate_credentials_t res)
{
gnutls_datum_t tmp;
int ret;
unsigned size, i;
opaque *pdata;
/* Generate the RDN sequence
* This will be sent to clients when a certificate
* request message is sent.
*/
/* FIXME: in case of a client it is not needed
* to do that. This would save time and memory.
* However we don't have that information available
* here.
*/
size = 0;
for (i = 0; i < res->x509_ncas; i++)
{
if ((ret = gnutls_x509_crt_get_raw_dn
(res->x509_ca_list[i], &tmp)) < 0)
{
gnutls_assert ();
return ret;
}
size += (2 + tmp.size);
_gnutls_free_datum (&tmp);
}
if (res->x509_rdn_sequence.data != NULL)
gnutls_free (res->x509_rdn_sequence.data);
res->x509_rdn_sequence.data =
gnutls_malloc (size);
if (res->x509_rdn_sequence.data == NULL)
{
gnutls_assert ();
return GNUTLS_E_MEMORY_ERROR;
}
res->x509_rdn_sequence.size = size;
pdata = res->x509_rdn_sequence.data;
for (i = 0; i < res->x509_ncas; i++)
{
if ((ret = gnutls_x509_crt_get_raw_dn
(res->x509_ca_list[i], &tmp)) < 0)
{
_gnutls_free_datum
(&res->x509_rdn_sequence);
gnutls_assert ();
return ret;
}
_gnutls_write_datum16 (pdata, tmp);
pdata += (2 + tmp.size);
_gnutls_free_datum (&tmp);
}
return 0;
}
Take some time to read and understand this code. Really. I'll be here waiting to explain it when you are finished.
The res->x509_ca_list variable contains the entire list of CA's stored in memory so far. It is initially empty. After reading the first file, it will contain one certificate. After reading the second file, it will contain two certificates, and so on.
What is happening here is that FOR EVERY certificate to add, the entire list of certificates is iterated, not just once but twice! The computational complexity of invoking the function is O(2*n^2) where n is the number of certificate names to be added. The first iteration is to compute the size of the string to hold the CA names. The actual data is discarded. The second iteration calls the same function, for the same data, but now store the output in the appropriate place.
The first step to optimize this is to realize that you don't need to iterate through all CAs every time a new one has been added. Adding the name for the most recently added certificate should be sufficient. Since more than one CA can be added at each time, the function needs to take another parameter: the number of recently added CAs for which to pre-compute the names for.
Our new code will look like:
static int
add_new_crt_to_rdn_seq (gnutls_certificate_credentials_t res, int new)
{
gnutls_datum_t tmp;
int ret;
size_t newsize;
unsigned char *newdata;
unsigned i;
/* Add DN of the last added CAs to the RDN sequence
* This will be sent to clients when a certificate
* request message is sent.
*/
/* FIXME: in case of a client it is not needed
* to do that. This would save time and memory.
* However we don't have that information available
* here.
* Further, this function is now much more efficient,
* so optimizing that is less important.
*/
for (i = res->x509_ncas - new; i < res->x509_ncas; i++)
{
if ((ret = gnutls_x509_crt_get_raw_dn
(res->x509_ca_list[i], &tmp)) < 0)
{
gnutls_assert ();
return ret;
}
newsize = res->x509_rdn_sequence.size +
2 + tmp.size;
if (newsize < res->x509_rdn_sequence.size)
{
gnutls_assert ();
_gnutls_free_datum (&tmp);
return GNUTLS_E_SHORT_MEMORY_BUFFER;
}
newdata = gnutls_realloc
(res->x509_rdn_sequence.data, newsize);
if (newdata == NULL)
{
gnutls_assert ();
_gnutls_free_datum (&tmp);
return GNUTLS_E_MEMORY_ERROR;
}
_gnutls_write_datum16 (newdata +
res->x509_rdn_sequence.size, tmp);
_gnutls_free_datum (&tmp);
res->x509_rdn_sequence.size = newsize;
res->x509_rdn_sequence.data = newdata;
}
return 0;
}
I changed the function name, to reflect that it now just update the list of names for a set of recently added certificates. That also helps to find and update all callers of the old function.
As you can see, this function should be of complexity O(n) instead, since it just adds the name of the most recently added CA's.
But is it faster in practice? Let's check it! First, remove the if (i++ > 20) break; statement in the test code, so that we do the full test. First link against our old libgnutls.a and run the old test case again, for illustrative purposes.
jas@mocca:~$ gcc -o foo foo.c /usr/lib/libgnutls.a -lgcrypt -ltasn1 -lz
jas@mocca:~$ time ./foo
real 0m40.756s
user 0m40.679s
sys 0m0.052s
jas@mocca:~$
Again, it takes around 40 seconds. Now recompile against our modified libgnutls and run the same test:
jas@mocca:~$ gcc -o foo foo.c /home/jas/src/gnutls/lib/.libs/libgnutls.a -lgcrypt -ltasn1 -lz
jas@mocca:~$ time ./foo
real 0m0.288s
user 0m0.280s
sys 0m0.012s
jas@mocca:~$
Wow! Down from 40 seconds to 0.3 seconds. Let's take a look at the callgrind output now.
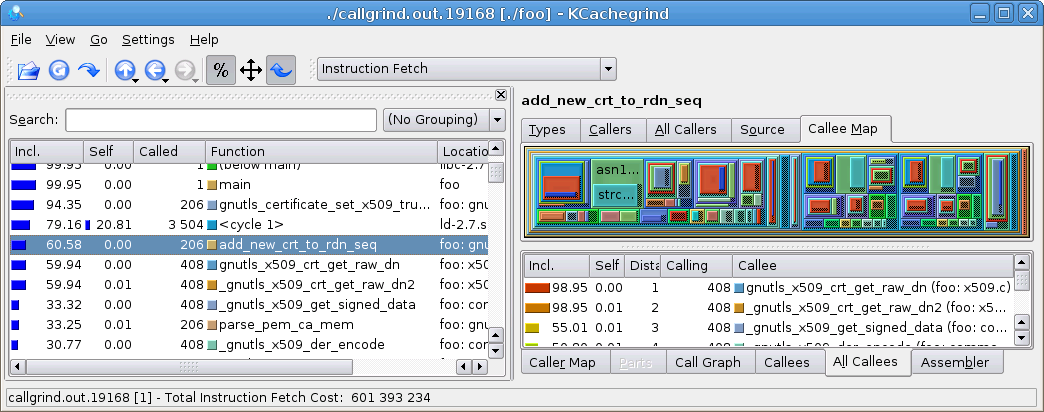
The code now spends around 60 % of the time in add_new_crt_to_rdn_seq() which seems reasonable. There are 206 files in /etc/ssl/certs, which explains the call count. Some of the files actually contain several CA certificates (in particular /etc/ssl/certs/ca-certificates.crt contains a lot of certificates), which explains why gnutls_x509_crt_get_raw_dn is called 408 times.
At this point, I stopped optimizing the code further.

