Around a year ago I discussed two concerns with software release archives (tarball artifacts) that could be improved to increase confidence in the supply-chain security of software releases. Repeating the goals for simplicity:
- Release artifacts should be built in a way that can be reproduced by others
- It should be possible to build a project from source tarball that doesn’t contain any generated or vendor files (e.g., in the style of git-archive).
While implementing these ideas for a small project was accomplished within weeks – see my announcement of Libntlm version 1.8 – adressing this in complex projects uncovered concerns with tools that had to be addressed, and things stalled for many months pending that work.
I had the notion that these two goals were easy and shouldn’t be hard to accomplish. I still believe that, but have had to realize that improving tooling to support these goals takes time. It seems clear that these concepts are not universally agreed on and implemented generally.
I’m now happy to recap some of the work that led to releases of libtasn1 v4.20.0, inetutils v2.6, libidn2 v2.3.8, libidn v1.43. These releases all achieve these goals. I am working on a bunch of more projects to support these ideas too.
What have the obstacles so far been to make this happen? It may help others who are in the same process of addressing these concerns to have a high-level introduction to the issues I encountered. Source code for projects above are available and anyone can look at the solutions to learn how the problems are addressed.
First let’s look at the problems we need to solve to make “git-archive” style tarballs usable:
Version Handling
To build usable binaries from a minimal tarballs, it need to know which version number it is. Traditionally this information was stored inside configure.ac in git. However I use gnulib’s git-version-gen to infer the version number from the git tag or git commit instead. The git tag information is not available in a git-archive tarball. My solution to this was to make use of the export-subst feature of the .gitattributes file. I store the file .tarball-version-git in git containing the magic cookie like this:
$Format:%(describe)$
With this, git-archive will replace with a useful version identifier on export, see the libtasn1 patch to achieve this. To make use of this information, the git-version-gen script was enhanced to read this information, see the gnulib patch. This is invoked by ./configure to figure out which version number the package is for.
Translations
We want translations to be included in the minimal source tarball for it to be buildable. Traditionally these files are retrieved by the maintainer from the Translation project when running ./bootstrap, however there are two problems with this. The first one is that there is no strong authentication or versioning information on this data, the tools just download and place whatever wget downloaded into your source tree (printf-style injection attack anyone?). We could improve this (e.g., publish GnuPG signed translations messages with clear versioning), however I did not work on that further. The reason is that I want to support offline builds of packages. Downloading random things from the Internet during builds does not work when building a Debian package, for example. The translation project could solve this by making a monthly tarball with their translations available, for distributors to pick up and provide as a separate package that could be used as a build dependency. However that is not how these tools and projects are designed. Instead I reverted back to storing translations in git, something that I did for most projects back when I was using CVS 20 years ago. Hooking this into ./bootstrap and gettext workflow can be tricky (ideas for improvement most welcome!), but I used a simple approach to store all directly downloaded po/*.po files directly as po/*.po.in and make the ./bootstrap tool move them in place, see the libidn2 commit followed by the actual ‘make update-po’ commit with all the translations where one essential step is:
# Prime po/*.po from fall-back copy stored in git.
for poin in po/*.po.in; do
po=$(echo $poin | sed 's/.in//')
test -f $po || cp -v $poin $po
done
ls po/*.po | sed 's|.*/||; s|\.po$||' > po/LINGUAS
Fetching vendor files like gnulib
Most build dependencies are in the shape of “You need a C compiler”. However some come in the shape of “source-code files intended to be vendored”, and gnulib is a huge repository of such files. The latter is a problem when building from a minimal git archive. It is possible to consider translation files as a class of vendor files, since they need to be copied verbatim into the project build directory for things to work. The same goes for *.m4 macros from the GNU Autoconf Archive. However I’m not confident that the solution for all vendor files must be the same. For translation files and for Autoconf Archive macros, I have decided to put these files into git and merge them manually occasionally. For gnulib files, in some projects like OATH Toolkit I also store all gnulib files in git which effectively resolve this concern. (Incidentally, the reason for doing so was originally that running ./bootstrap took forever since there is five gnulib instances used, which is no longer the case since gnulib-tool was rewritten in Python.) For most projects, however, I rely on ./bootstrap to fetch a gnulib git clone when building. I like this model, however it doesn’t work offline. One way to resolve this is to make the gnulib git repository available for offline use, and I’ve made some effort to make this happen via a Gnulib Git Bundle and have explained how to implement this approach for Debian packaging. I don’t think that is sufficient as a generic solution though, it is mostly applicable to building old releases that uses old gnulib files. It won’t work when building from CI/CD pipelines, for example, where I have settled to use a crude way of fetching and unpacking a particular gnulib snapshot, see this Libntlm patch. This is much faster than working with git submodules and cloning gnulib during ./bootstrap. Essentially this is doing:
GNULIB_REVISION=$(. bootstrap.conf >&2; echo $GNULIB_REVISION)
wget -nv https://gitlab.com/libidn/gnulib-mirror/-/archive/$GNULIB_REVISION/gnulib-mirror-$GNULIB_REVISION.tar.gz
gzip -cd gnulib-mirror-$GNULIB_REVISION.tar.gz | tar xf -
rm -fv gnulib-mirror-$GNULIB_REVISION.tar.gz
export GNULIB_SRCDIR=$PWD/gnulib-mirror-$GNULIB_REVISION
./bootstrap --no-git
./configure
make
Test the git-archive tarball
This goes without saying, but if you don’t test that building from a git-archive style tarball works, you are likely to regress at some point. Use CI/CD techniques to continuously test that a minimal git-archive tarball leads to a usable build.
Mission Accomplished
So that wasn’t hard, was it? You should now be able to publish a minimal git-archive tarball and users should be able to build your project from it.
I recommend naming these archives as PROJECT-vX.Y.Z-src.tar.gz replacing PROJECT with your project name and X.Y.Z with your version number. The archive should have only one sub-directory named PROJECT-vX.Y.Z/ containing all the source-code files. This differentiate it against traditional PROJECT-X.Y.Z.tar.gz tarballs in that it embeds the git tag (which typically starts with v) and contains a wildcard-friendly -src substring. Alas there is no consistency around this naming pattern, and GitLab, GitHub, Codeberg etc all seem to use their own slightly incompatible variant.
Let’s go on to see what is needed to achieve reproducible “make dist” source tarballs. This is the release artifact that most users use, and they often contain lots of generated files and vendor files. These files are included to make it easy to build for the user. What are the challenges to make these reproducible?
Build dependencies causing different generated content
The first part is to realize that if you use tool X with version A to generate a file that goes into the tarball, version B of that tool may produce different outputs. This is a generic concern and it cannot be solved. We want our build tools to evolve and produce better outputs over time. What can be addressed is to avoid needless differences. For example, many tools store timestamps and versioning information in the generated files. This causes needless differences, which makes audits harder. I have worked on some of these, like Autoconf Archive timestamps but solving all of these examples will take a long time, and some upstream are reluctant to incorporate these changes. My approach meanwhile is to build things using similar environments, and compare the outputs for differences. I’ve found that the various closely related forks of GNU/Linux distributions are useful for this. Trisquel 11 is based on Ubuntu 22.04, and building my projects using both and comparing the differences only give me the relevant differences to improve. This can be extended to compare AlmaLinux with RockyLinux (for both versions 8 and 9), Devuan 5 against Debian 12, PureOS 10 with Debian 11, and so on.
Timestamps
Sometimes tools store timestamps in files in a way that is harder to fix. Two notable examples of this are *.po translation files and Texinfo manuals. For translation files, I have resolved this by making sure the files use a predictable POT-Creation-Date timestamp, and I set it to the modification timestamps of the NEWS file in the repository (which I set to the git commit of the latest commit elsewhere) like this:
dist-hook: po-CreationDate-to-mtime-NEWS
.PHONY: po-CreationDate-to-mtime-NEWS
po-CreationDate-to-mtime-NEWS: mtime-NEWS-to-git-HEAD
$(AM_V_GEN)for p in $(distdir)/po/*.po $(distdir)/po/$(PACKAGE).pot; do \
if test -f "$$p"; then \
$(SED) -e 's,POT-Creation-Date: .*\\n",POT-Creation-Date: '"$$(env LC_ALL=C TZ=UTC0 stat --format=%y $(srcdir)/NEWS | cut -c1-16,31-)"'\\n",' < $$p > $$p.tmp && \
if cmp $$p $$p.tmp > /dev/null; then \
rm -f $$p.tmp; \
else \
mv $$p.tmp $$p; \
fi \
fi \
done
Similarily, I set a predictable modification time of the texinfo source file like this:
dist-hook: mtime-NEWS-to-git-HEAD
.PHONY: mtime-NEWS-to-git-HEAD
mtime-NEWS-to-git-HEAD:
$(AM_V_GEN)if test -e $(srcdir)/.git \
&& command -v git > /dev/null; then \
touch -m -t "$$(git log -1 --format=%cd \
--date=format-local:%Y%m%d%H%M.%S)" $(srcdir)/NEWS; \
fi
However I’ve realized that this needs to happen earlier and probably has to be run during ./configure time, because the doc/version.texi file is generated on first build before running ‘make dist‘ and for some reason the file is not rebuilt at release time. The Automake texinfo integration is a bit inflexible about providing hooks to extend the dependency tracking.
The method to address these differences isn’t really important, and they change over time depending on preferences. What is important is that the differences are eliminated.
ChangeLog
Traditionally ChangeLog files were manually prepared, and still is for some projects. I maintain git2cl but recently I’ve settled with gnulib’s gitlog-to-changelog because doing so avoids another build dependency (although the output formatting is different and arguable worse for my git commit style). So the ChangeLog files are generated from git history. This means a shallow clone will not produce the same ChangeLog file depending on how deep it was cloned. For Libntlm I simply disabled use of generated ChangeLog because I wanted to support an even more extreme form of reproducibility: I wanted to be able to reproduce the full “make dist” source archives from a minimal “git-archive” source archive. However for other projects I’ve settled with a middle ground. I realized that for ‘git describe‘ to produce reproducible outputs, the shallow clone needs to include the last release tag. So it felt acceptable to assume that the clone is not minimal, but instead has some but not all of the history. I settled with the following recipe to produce ChangeLog's covering all changes since the last release.
dist-hook: gen-ChangeLog
.PHONY: gen-ChangeLog
gen-ChangeLog:
$(AM_V_GEN)if test -e $(srcdir)/.git; then \
LC_ALL=en_US.UTF-8 TZ=UTC0 \
$(top_srcdir)/build-aux/gitlog-to-changelog \
--srcdir=$(srcdir) -- \
v$(PREV_VERSION)~.. > $(distdir)/cl-t && \
{ printf '\n\nSee the source repo for older entries\n' \
>> $(distdir)/cl-t && \
rm -f $(distdir)/ChangeLog && \
mv $(distdir)/cl-t $(distdir)/ChangeLog; } \
fi
I’m undecided about the usefulness of generated ChangeLog files within ‘make dist‘ archives. Before we have stable and secure archival of git repositories widely implemented, I can see some utility of this in case we lose all copies of the upstream git repositories. I can sympathize with the concept of ChangeLog files died when we started to generate them from git logs: the files no longer serve any purpose, and we can ask people to go look at the git log instead of reading these generated non-source files.
Long-term reproducible trusted build environment
Distributions comes and goes, and old releases of them goes out of support and often stops working. Which build environment should I chose to build the official release archives? To my knowledge only Guix offers a reliable way to re-create an older build environment (guix gime-machine) that have bootstrappable properties for additional confidence. However I had two difficult problems here. The first one was that I needed Guix container images that were usable in GitLab CI/CD Pipelines, and this side-tracked me for a while. The second one delayed my effort for many months, and I was inclined to give up. Libidn distribute a C# implementation. Some of the C# source code files included in the release tarball are generated. By what? You guess it, by a C# program, with the source code included in the distribution. This means nobody could reproduce the source tarball of Libidn without trusting someone elses C# compiler binaries, which were built from binaries of earlier releases, chaining back into something that nobody ever attempts to build any more and likely fail to build due to bit-rot. I had two basic choices, either remove the C# implementation from Libidn (which may be a good idea for other reasons, since the C and C# are unrelated implementations) or build the source tarball on some binary-only distribution like Trisquel. Neither felt appealing to me, but a late christmas gift of a reproducible Mono came to Guix that resolve this.
Embedded images in Texinfo manual
For Libidn one section of the manual has an image illustrating some concepts. The PNG, PDF and EPS outputs were generated via fig2dev from a *.fig file (hello 1985!) that I had stored in git. Over time, I had also started to store the generated outputs because of build issues. At some point, it was possible to post-process the PDF outputs with grep to remove some timestamps, however with compression this is no longer possible and actually the grep command I used resulted in a 0-byte output file. So my embedded binaries in git was no longer reproducible. I first set out to fix this by post-processing things properly, however I then realized that the *.fig file is not really easy to work with in a modern world. I wanted to create an image from some text-file description of the image. Eventually, via the Guix manual on guix graph, I came to re-discover the graphviz language and tool called dot (hello 1993!). All well then? Oh no, the PDF output embeds timestamps. Binary editing of PDF’s no longer work through simple grep, remember? I was back where I started, and after some (soul- and web-) searching I discovered that Ghostscript (hello 1988!) pdfmarks could be used to modify things here. Cooperating with automake’s texinfo rules related to make dist proved once again a worthy challenge, and eventually I ended up with a Makefile.am snippet to build images that could be condensed into:
info_TEXINFOS = libidn.texi
libidn_TEXINFOS += libidn-components.png
imagesdir = $(infodir)
images_DATA = libidn-components.png
EXTRA_DIST += components.dot
DISTCLEANFILES = \
libidn-components.eps libidn-components.png libidn-components.pdf
libidn-components.eps: $(srcdir)/components.dot
$(AM_V_GEN)$(DOT) -Nfontsize=9 -Teps < $< > $@.tmp
$(AM_V_at)! grep %%CreationDate $@.tmp
$(AM_V_at)mv $@.tmp $@
libidn-components.pdf: $(srcdir)/components.dot
$(AM_V_GEN)$(DOT) -Nfontsize=9 -Tpdf < $< > $@.tmp
# A simple sed on CreationDate is no longer possible due to compression.
# 'exiftool -CreateDate' is alternative to 'gs', but adds ~4kb to file.
# Ghostscript add <1kb. Why can't 'dot' avoid setting CreationDate?
$(AM_V_at)printf '[ /ModDate ()\n /CreationDate ()\n /DOCINFO pdfmark\n' > pdfmarks
$(AM_V_at)$(GS) -q -dBATCH -dNOPAUSE -sDEVICE=pdfwrite -sOutputFile=$@.tmp2 $@.tmp pdfmarks
$(AM_V_at)rm -f $@.tmp pdfmarks
$(AM_V_at)mv $@.tmp2 $@
libidn-components.png: $(srcdir)/components.dot
$(AM_V_GEN)$(DOT) -Nfontsize=9 -Tpng < $< > $@.tmp
$(AM_V_at)mv $@.tmp $@
pdf-recursive: libidn-components.pdf
dvi-recursive: libidn-components.eps
ps-recursive: libidn-components.eps
info-recursive: $(top_srcdir)/.version libidn-components.png
Surely this can be improved, but I’m not yet certain in what way is the best one forward. I like having a text representation as the source of the image. I’m sad that the new image size is ~48kb compared to the old image size of ~1kb. I tried using exiftool -CreateDate as an alternative to GhostScript, but using it to remove the timestamp added ~4kb to the file size and naturally I was appalled by this ignorance of impending doom.
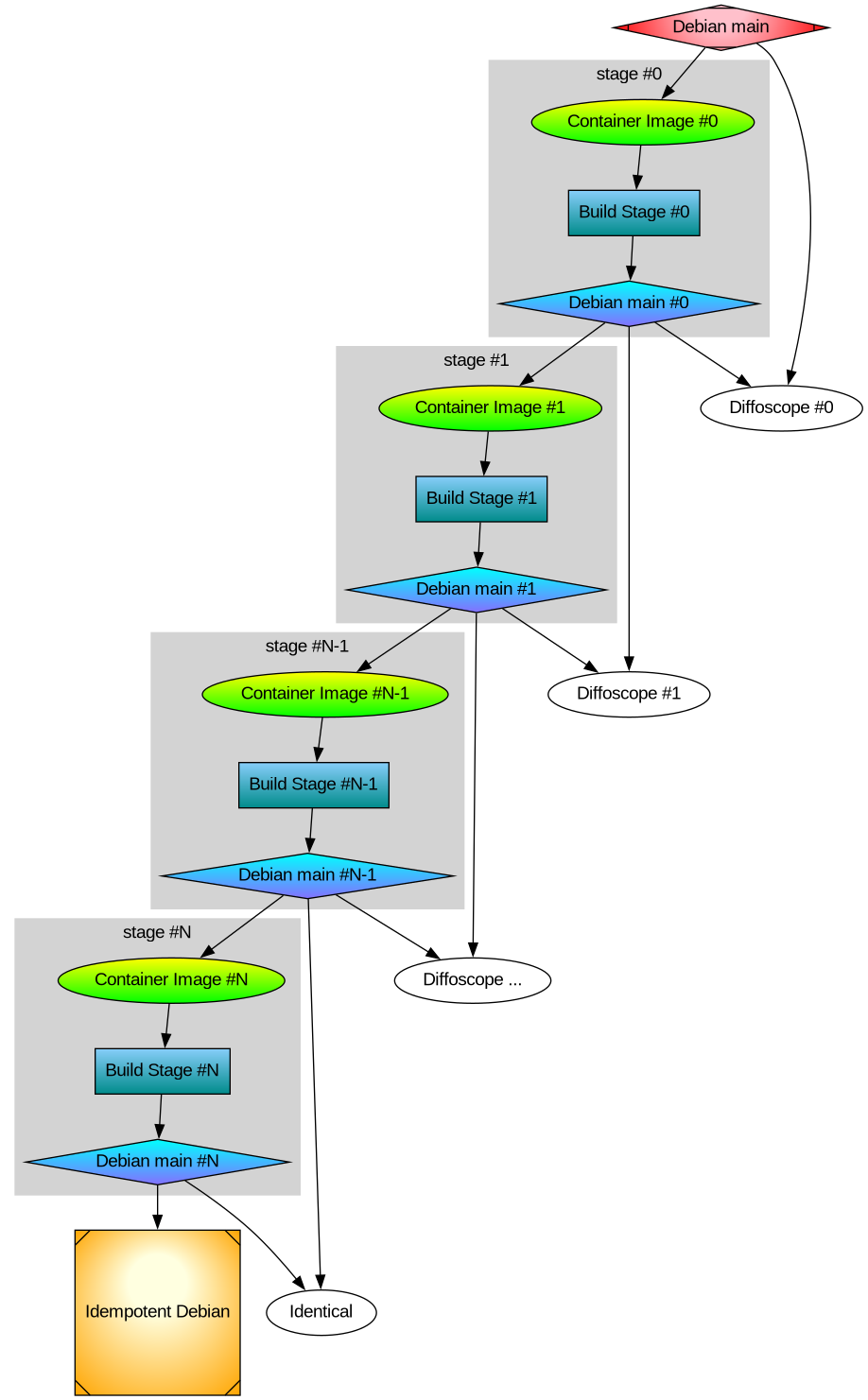
Test reproducibility of tarball
Again, you need to continuously test the properties you desire. This means building your project twice using different environments and comparing the results. I’ve settled with a small GitLab CI/CD pipeline job that perform bit-by-bit comparison of generated ‘make dist’ archives. It also perform bit-by-bit comparison of generated ‘git-archive’ artifacts. See the Libidn2 .gitlab-ci.yml 0-compare job which essentially is:
0-compare:
image: alpine:latest
stage: repro
needs: [ B-AlmaLinux8, B-AlmaLinux9, B-RockyLinux8, B-RockyLinux9, B-Trisquel11, B-Ubuntu2204, B-PureOS10, B-Debian11, B-Devuan5, B-Debian12, B-gcc, B-clang, B-Guix, R-Guix, R-Debian12, R-Ubuntu2404, S-Trisquel10, S-Ubuntu2004 ]
script:
- cd out
- sha256sum */*.tar.* */*/*.tar.* | sort | grep -- -src.tar.
- sha256sum */*.tar.* */*/*.tar.* | sort | grep -v -- -src.tar.
- sha256sum */*.tar.* */*/*.tar.* | sort | uniq -c -w64 | sort -rn
- sha256sum */*.tar.* */*/*.tar.* | grep -- -src.tar. | sort | uniq -c -w64 | grep -v '^ 1 '
- sha256sum */*.tar.* */*/*.tar.* | grep -v -- -src.tar. | sort | uniq -c -w64 | grep -v '^ 1 '
# Confirm modern git-archive tarball reproducibility
- cmp b-almalinux8/src/*.tar.gz b-almalinux9/src/*.tar.gz
- cmp b-almalinux8/src/*.tar.gz b-rockylinux8/src/*.tar.gz
- cmp b-almalinux8/src/*.tar.gz b-rockylinux9/src/*.tar.gz
- cmp b-almalinux8/src/*.tar.gz b-debian12/src/*.tar.gz
- cmp b-almalinux8/src/*.tar.gz b-devuan5/src/*.tar.gz
- cmp b-almalinux8/src/*.tar.gz r-guix/src/*.tar.gz
- cmp b-almalinux8/src/*.tar.gz r-debian12/src/*.tar.gz
- cmp b-almalinux8/src/*.tar.gz r-ubuntu2404/src/*v2.*.tar.gz
# Confirm old git-archive (export-subst but long git describe) tarball reproducibility
- cmp b-trisquel11/src/*.tar.gz b-ubuntu2204/src/*.tar.gz
# Confirm really old git-archive (no export-subst) tarball reproducibility
- cmp b-debian11/src/*.tar.gz b-pureos10/src/*.tar.gz
# Confirm 'make dist' generated tarball reproducibility
- cmp b-almalinux8/*.tar.gz b-rockylinux8/*.tar.gz
- cmp b-almalinux9/*.tar.gz b-rockylinux9/*.tar.gz
- cmp b-pureos10/*.tar.gz b-debian11/*.tar.gz
- cmp b-devuan5/*.tar.gz b-debian12/*.tar.gz
- cmp b-trisquel11/*.tar.gz b-ubuntu2204/*.tar.gz
- cmp b-guix/*.tar.gz r-guix/*.tar.gz
# Confirm 'make dist' from git-archive tarball reproducibility
- cmp s-trisquel10/*.tar.gz s-ubuntu2004/*.tar.gz
Notice that I discovered that ‘git archive’ outputs differ over time too, which is natural but a bit of a nuisance. The output of the job is illuminating in the way that all SHA256 checksums of generated tarballs are included, for example the libidn2 v2.3.8 job log:
$ sha256sum */*.tar.* */*/*.tar.* | sort | grep -v -- -src.tar.
368488b6cc8697a0a937b9eb307a014396dd17d3feba3881e6911d549732a293 b-trisquel11/libidn2-2.3.8.tar.gz
368488b6cc8697a0a937b9eb307a014396dd17d3feba3881e6911d549732a293 b-ubuntu2204/libidn2-2.3.8.tar.gz
59db2d045fdc5639c98592d236403daa24d33d7c8db0986686b2a3056dfe0ded b-debian11/libidn2-2.3.8.tar.gz
59db2d045fdc5639c98592d236403daa24d33d7c8db0986686b2a3056dfe0ded b-pureos10/libidn2-2.3.8.tar.gz
5bd521d5ecd75f4b0ab0fc6d95d444944ef44a84cad859c9fb01363d3ce48bb8 s-trisquel10/libidn2-2.3.8.tar.gz
5bd521d5ecd75f4b0ab0fc6d95d444944ef44a84cad859c9fb01363d3ce48bb8 s-ubuntu2004/libidn2-2.3.8.tar.gz
7f1dcdea3772a34b7a9f22d6ae6361cdcbe5513e3b6485d40100b8565c9b961a b-almalinux8/libidn2-2.3.8.tar.gz
7f1dcdea3772a34b7a9f22d6ae6361cdcbe5513e3b6485d40100b8565c9b961a b-rockylinux8/libidn2-2.3.8.tar.gz
8031278157ce43b5813f36cf8dd6baf0d9a7f88324ced796765dcd5cd96ccc06 b-clang/libidn2-2.3.8.tar.gz
8031278157ce43b5813f36cf8dd6baf0d9a7f88324ced796765dcd5cd96ccc06 b-debian12/libidn2-2.3.8.tar.gz
8031278157ce43b5813f36cf8dd6baf0d9a7f88324ced796765dcd5cd96ccc06 b-devuan5/libidn2-2.3.8.tar.gz
8031278157ce43b5813f36cf8dd6baf0d9a7f88324ced796765dcd5cd96ccc06 b-gcc/libidn2-2.3.8.tar.gz
8031278157ce43b5813f36cf8dd6baf0d9a7f88324ced796765dcd5cd96ccc06 r-debian12/libidn2-2.3.8.tar.gz
acf5cbb295e0693e4394a56c71600421059f9c9bf45ccf8a7e305c995630b32b r-ubuntu2404/libidn2-2.3.8.tar.gz
cbdb75c38100e9267670b916f41878b6dbc35f9c6cbe60d50f458b40df64fcf1 b-almalinux9/libidn2-2.3.8.tar.gz
cbdb75c38100e9267670b916f41878b6dbc35f9c6cbe60d50f458b40df64fcf1 b-rockylinux9/libidn2-2.3.8.tar.gz
f557911bf6171621e1f72ff35f5b1825bb35b52ed45325dcdee931e5d3c0787a b-guix/libidn2-2.3.8.tar.gz
f557911bf6171621e1f72ff35f5b1825bb35b52ed45325dcdee931e5d3c0787a r-guix/libidn2-2.3.8.tar.gz
I’m sure I have forgotten or suppressed some challenges (sprinkling LANG=C TZ=UTC0 helps) related to these goals, but my hope is that this discussion of solutions will inspire you to implement these concepts for your software project too. Please share your thoughts and additional insights in a comment below. Enjoy Happy Hacking in the course of practicing this!